Groq สตาร์ตอัพผู้พัฒนาชิป GroqChip 1 สำหรับการรันโมเดลปัญญาประดิษฐ์ LLM และผู้ให้บริการ LLM แบบคลาวด์ระบุถึงผลทดสอบของ ArtificialAnalysis.ai ที่แสดงให้เห็นว่า Groq เป็นผู้ให้บริการที่สามารถประมวลผล LLM ได้เร็วที่สุดในตลาด
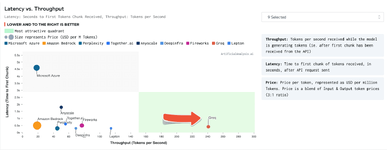
โมเดลที่ใช้ทดสอบเป็นโมเดล Llama 2 70B ที่มีคลาวด์หลายเจ้าให้บริการกัน รวมถึงคลาวด์รายใหญ่อย่าง Amazon Bedrock และ Azure แต่จุดที่ Groq นำมาเน้นคือความเร็วในการตอบ ที่ระยะเวลาจนถึงการตอบ 100 token แรกนั้นกินเวลาเพียง 0.7 วินาที และอัตราการตอบรวมได้เร็วกว่า 240 token ต่อวินาที นับว่าเร็วกว่าคู่แข่งอันดับสองแบบห่างไกล (Lepton รันได้สูงกว่า 120 token ต่อวินาทีไปเล็กน้อย)
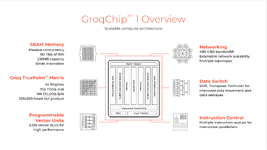
ชิป GroqChip 1 นั้นทาง Groq เรียกว่าเป็น LPU หรือ language processing unit จุดแตกต่างคือในชิปมี SRAM มากถึง 230MB สำหรับการรัน AI โดยเฉพาะ สถาปัตยกรรมโดยรวมเรียบง่ายกว่าชิปกราฟิก
ตอนนี้โมเดลที่ดีที่สุดที่ Groq ให้บริการคือ Mixtral 8x7B 32k สามารถรันได้ที่ระดับ 500 token ต่อวินาที และเว็บ Groq เปิดให้ทุกคนทดสอบได้โดยไม่ต้องสมัครสมาชิก
ที่มา - Groq


Topics:
LLM
Artificial Intelligence
อ่านต่อ...
โมเดลที่ใช้ทดสอบเป็นโมเดล Llama 2 70B ที่มีคลาวด์หลายเจ้าให้บริการกัน รวมถึงคลาวด์รายใหญ่อย่าง Amazon Bedrock และ Azure แต่จุดที่ Groq นำมาเน้นคือความเร็วในการตอบ ที่ระยะเวลาจนถึงการตอบ 100 token แรกนั้นกินเวลาเพียง 0.7 วินาที และอัตราการตอบรวมได้เร็วกว่า 240 token ต่อวินาที นับว่าเร็วกว่าคู่แข่งอันดับสองแบบห่างไกล (Lepton รันได้สูงกว่า 120 token ต่อวินาทีไปเล็กน้อย)
ชิป GroqChip 1 นั้นทาง Groq เรียกว่าเป็น LPU หรือ language processing unit จุดแตกต่างคือในชิปมี SRAM มากถึง 230MB สำหรับการรัน AI โดยเฉพาะ สถาปัตยกรรมโดยรวมเรียบง่ายกว่าชิปกราฟิก
ตอนนี้โมเดลที่ดีที่สุดที่ Groq ให้บริการคือ Mixtral 8x7B 32k สามารถรันได้ที่ระดับ 500 token ต่อวินาที และเว็บ Groq เปิดให้ทุกคนทดสอบได้โดยไม่ต้องสมัครสมาชิก
ที่มา - Groq
Topics:
LLM
Artificial Intelligence
อ่านต่อ...