- เข้าร่วม
- 1 มิถุนายน 2011
- ข้อความ
- 10,349
- กระทู้ ผู้เขียน
- #1
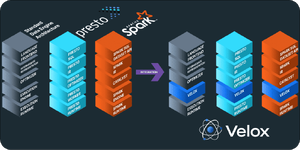
เมื่อเดือนมีนาคมที่ผ่านมา Meta เปิดตัวโครงการ Velox เป็น unified execution engine กลางสำหรับฐานข้อมูลหรือระบบจัดการข้อมูลหลายรูปแบบ ตอบโจทย์ระดับโครงสร้างพื้นฐานของบริษัทใหญ่ระดับ Meta ที่ต้องใช้ฐานข้อมูลหลากหลาย และซับซ้อนขึ้นเรื่อยๆ
Velox จึงถูกสร้างขึ้นเพื่อจัดระเบียบวิธีการเก็บและเรียกใช้ข้อมูลที่แตกต่างกัน ช่วยลดความซ้ำซ้อนในการพัฒนา และรีดประสิทธิภาพของการเก็บข้อมูลให้ดีขึ้น แก้ปัญหาเอนจินแต่ละตัวมีวิธี optimized ที่แตกต่างกัน
เบื้องต้น Velox รองรับฐานข้อมูล 3 รูปแบบ ได้แก่ Apache Spark, Presto, PyTorch สำหรับงานปัญญาประดิษฐ์ ซึ่งทั้ง 3 แบบเป็นระบบที่ใช้บ่อยภายในบริษัท Meta


สิ่งที่ Velox ทำคือปรับแต่งเอนจินข้อมูลเหล่านี้ตอนรันไทม์ เช่น การเรียงลำดับข้อมูล ทำฟิลเตอร์ข้อมูล ทำ normalization ของอาร์เรย์ ฯลฯ โดยคำนึงถึงรูปแบบงานที่พบบ่อยในการประมวลผลยุคใหม่ ตัวอย่างเบนช์มาร์คของ Meta กับฐานข้อมูล Presto พบว่าการคิวรีข้อมูลเร็วขึ้นได้ถึง 6-7 เท่าเลยทีเดียว (ในหน้า GitHub ของโครงการให้นิยามว่าตัวเองเป็น database acceleration library)

โครงการ Velox เปิดเป็นโอเพนซอร์สบน GitHub และมีบริษัทอื่นเข้ามาช่วยพัฒนาแล้ว เช่น อินเทลมาทำตัวเชื่อมต่อกับ Spark ในชื่อโครงการ Gluten
เนื่องจาก Velox ไม่ได้ยุ่งกับระดับชั้นบนๆ ของฐานข้อมูล เช่น ตัวอ่านคำสั่ง SQL, ตัวปรับแต่งคิวรี จึงไม่ได้มีกลุ่มเป้าหมายคือผู้ใช้งานฐานข้อมูล แต่ออกแบบมาเพื่อนักพัฒนาใช้ปรับแต่งประสิทธิภาพของฐานข้อมูลที่ใช้งานอยู่ได้
ที่มา - Meta Engineering
Topics:
Meta
Database
Development
Apache Spark
Presto
PyTorch
อ่านต่อ...
Velox จึงถูกสร้างขึ้นเพื่อจัดระเบียบวิธีการเก็บและเรียกใช้ข้อมูลที่แตกต่างกัน ช่วยลดความซ้ำซ้อนในการพัฒนา และรีดประสิทธิภาพของการเก็บข้อมูลให้ดีขึ้น แก้ปัญหาเอนจินแต่ละตัวมีวิธี optimized ที่แตกต่างกัน
เบื้องต้น Velox รองรับฐานข้อมูล 3 รูปแบบ ได้แก่ Apache Spark, Presto, PyTorch สำหรับงานปัญญาประดิษฐ์ ซึ่งทั้ง 3 แบบเป็นระบบที่ใช้บ่อยภายในบริษัท Meta
สิ่งที่ Velox ทำคือปรับแต่งเอนจินข้อมูลเหล่านี้ตอนรันไทม์ เช่น การเรียงลำดับข้อมูล ทำฟิลเตอร์ข้อมูล ทำ normalization ของอาร์เรย์ ฯลฯ โดยคำนึงถึงรูปแบบงานที่พบบ่อยในการประมวลผลยุคใหม่ ตัวอย่างเบนช์มาร์คของ Meta กับฐานข้อมูล Presto พบว่าการคิวรีข้อมูลเร็วขึ้นได้ถึง 6-7 เท่าเลยทีเดียว (ในหน้า GitHub ของโครงการให้นิยามว่าตัวเองเป็น database acceleration library)
โครงการ Velox เปิดเป็นโอเพนซอร์สบน GitHub และมีบริษัทอื่นเข้ามาช่วยพัฒนาแล้ว เช่น อินเทลมาทำตัวเชื่อมต่อกับ Spark ในชื่อโครงการ Gluten
เนื่องจาก Velox ไม่ได้ยุ่งกับระดับชั้นบนๆ ของฐานข้อมูล เช่น ตัวอ่านคำสั่ง SQL, ตัวปรับแต่งคิวรี จึงไม่ได้มีกลุ่มเป้าหมายคือผู้ใช้งานฐานข้อมูล แต่ออกแบบมาเพื่อนักพัฒนาใช้ปรับแต่งประสิทธิภาพของฐานข้อมูลที่ใช้งานอยู่ได้
ที่มา - Meta Engineering
Topics:
Meta
Database
Development
Apache Spark
Presto
PyTorch
อ่านต่อ...