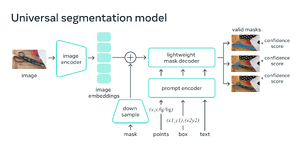
Meta เผยแพร่โครงการ Segment Anything โมเดล AI สำหรับงานแยกแยะวัตถุในรูปภาพและวิดีโอ (Segmentation) มีจุดเด่นคือความสามารถในการแยกแยะวัตถุต่าง ๆ แม้จะไม่เคยเทรนให้รู้จักวัตถุนั้นมาก่อน และมาพร้อมเครื่องมือที่วาดเส้นขอบวัตถุให้อัตโนมัติ
ในงานที่เผยแพร่นี้ Meta นำเสนอสองอย่างได้แก่ Segment Anything Model (SAM) โมเดลสำหรับการแยกแยะวัตถุ เผยแพร่ภายใต้สัญญา Apache 2.0 และข้อมูล 1 พันล้านดาต้าเซต สำหรับงาน Segmentation (SA-1B) อนุญาตให้ใช้สำหรับงานวิจัย
Meta บอกว่า Segmentation เป็นงานตั้งต้นของ Computer Vision ที่ต้องอาศัยการเทรนข้อมูลพื้นฐานก่อน แต่ด้วยชุดโมเดล SAM นี้ จะสามารถนำไปต่อยอดงานพัฒนาได้หลากหลายทันที เช่น การแยกแยะวัตถุแบบเรียลไทม์ใน AR/VR, การนำระบบจับวัตถุไปใช้กับแอปตัดต่อวิดีโอ หรือในงานวิจัยอื่น ๆ
Meta ยังสร้างเว็บสำหรับทดลองใช้เดโมของ Segment Anything ที่ผู้ใช้งานสามารถลองอัปโหลดรูปของตนเองได้ด้วย
ที่มา: Meta


Topics:
Meta
Computer Vision
Artificial Intelligence
อ่านต่อ...
ในงานที่เผยแพร่นี้ Meta นำเสนอสองอย่างได้แก่ Segment Anything Model (SAM) โมเดลสำหรับการแยกแยะวัตถุ เผยแพร่ภายใต้สัญญา Apache 2.0 และข้อมูล 1 พันล้านดาต้าเซต สำหรับงาน Segmentation (SA-1B) อนุญาตให้ใช้สำหรับงานวิจัย
Meta บอกว่า Segmentation เป็นงานตั้งต้นของ Computer Vision ที่ต้องอาศัยการเทรนข้อมูลพื้นฐานก่อน แต่ด้วยชุดโมเดล SAM นี้ จะสามารถนำไปต่อยอดงานพัฒนาได้หลากหลายทันที เช่น การแยกแยะวัตถุแบบเรียลไทม์ใน AR/VR, การนำระบบจับวัตถุไปใช้กับแอปตัดต่อวิดีโอ หรือในงานวิจัยอื่น ๆ
Meta ยังสร้างเว็บสำหรับทดลองใช้เดโมของ Segment Anything ที่ผู้ใช้งานสามารถลองอัปโหลดรูปของตนเองได้ด้วย
ที่มา: Meta
Topics:
Meta
Computer Vision
Artificial Intelligence
อ่านต่อ...